Novel to Video AI: Complete Manuscript to Video Series Pipeline
Upload a novel manuscript and VoooAI auto-segments chapters into scenes with consistent characters across 10+ episodes on Kling O3, Seedance 2.0, and Wan2.6.
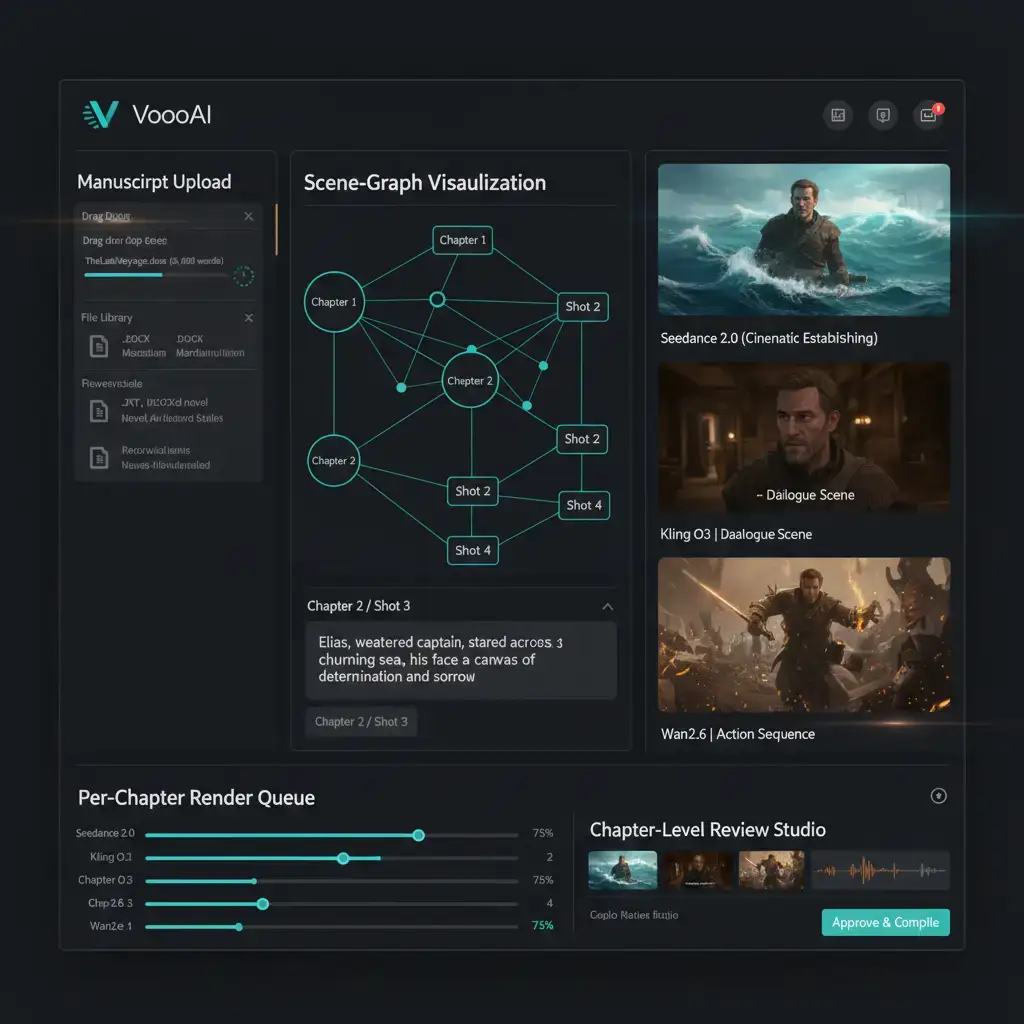
How do you turn a 50,000-word novel manuscript into a finished video series without spending months storyboarding, casting, and rendering each chapter by hand? VoooAI's novel-to-video AI workflow ingests a complete manuscript—5,000 words or more—and automatically segments chapters into visual scenes, generates consistent character portraits across 10+ episodes, and orchestrates three parallel AI video engines (Kling O3 for dialogue-heavy scenes, Wan2.6 for action sequences, Seedance 2.0 for cinematic establishing shots). A 10-chapter manuscript renders into serialized video content in under 2 hours of compute time, with no manual scene-by-scene prompting required.
According to [Gartner's AI adoption research](https://www.gartner.com/en/information-technology/insights/artificial-intelligence), 80% of organizations have adopted or plan to adopt intelligent automation by 2025, and AI-driven content production is the fastest-growing automation vertical. The novel-to-video pipeline is the logical extension of this trend: if generative AI can draft a manuscript and generate a marketing video, the missing link has been the end-to-end pipeline that connects both without manual engineering at every seam.
How VoooAI Segments a Novel Into Scenes Across Three Parallel Engines
The workflow opens with a chapter upload field that accepts TXT, DOCX, or Markdown files. A pre-processing node reads the manuscript, identifies chapter and paragraph boundaries, and constructs an internal scene graph. Each chapter is split into 3-7 shot-level beats based on dialogue density, action cues, and descriptive passages. The scene graph then fans out to three engine-specific renderers: Kling O3 receives dialogue-heavy scenes with character reference images pre-attached for lip-sync fidelity; Wan2.6 processes action beats with motion-intensity tokens so fight sequences and chase scenes retain spatial continuity; Seedance 2.0 handles establishing shots, environmental transitions, and montage sequences where visual quality rather than motion speed is the priority. Character consistency across engines is enforced by a shared reference-image pool. Upload a single face reference per protagonist at the top of the workflow, and every scene—regardless of which engine renders it—receives the same facial geometry, clothing palette, and lighting profile. According to [MarketsandMarkets' generative AI market outlook](https://www.marketsandmarkets.com/Market-Reports/generative-ai-market-142870584.html), the generative AI market is growing at a double-digit CAGR through 2030, and video generation is the leading sub-segment—exactly the macro trend that makes novel-to-video production a structurally viable format rather than an experimental novelty.
Three Novel-to-Video Pipeline Mistakes That Waste Render Credits
First, uploading a manuscript without cleaning formatting artifacts. Word processors embed invisible control characters, custom heading styles, and tracked changes that confuse the scene-graph parser. Export your manuscript as plain .txt or strict Markdown with H2 chapter headings and one blank line between paragraphs to get the cleanest parse. Second, expecting the AI to invent visual details that were never in the text. If a chapter describes a conversation in a featureless white room, the engine renders a featureless white room; literary subtext is not automatically translated into set design. Add a one-line visual style note at the top of each chapter—for example, 'Art Deco apartment, warm amber lighting, 1920s Paris'—to give the spatial AI system a production-design anchor without rewriting the prose. Third, rendering every chapter sequentially without checking the first few outputs. A character reference that works in well-lit establishing shots may break in dimly lit night scenes because the engine extrapolates the low-light face differently. Always validate the first three episodes before committing the full run, and tune your reference images using those early outputs.
Why VoooAI Beats Manual Chapter-by-Chapter Video Production
Traditional novel-to-video adaptation requires a screenwriter, a storyboard artist, a casting director, a costume designer, a cinematographer, and an editor—a team of six or more. Each chapter takes 2-3 weeks of production, pushing a 10-chapter novel to six months. VoooAI collapses this into a single upload-and-validate loop: upload the manuscript, validate the parsed scene graph, check the first three episodes, and release the full series. The workflow does not eliminate creative control—every scene can be re-rendered on any of the three engines with a single click—but it removes the mechanical repetition of manually reconstructing character references, shot framing, and pacing per chapter. According to [Statista's global AI market trajectory](https://www.statista.com/statistics/1365145/artificial-intelligence-market-size/), the global AI market is projected to reach $1,218 billion by 2030, and this scale of investment is precisely what enables parallel multi-engine rendering infrastructure to become accessible beyond enterprise production studios. The 24GB VRAM hardware requirement that seemed prohibitive a year ago is now a standard consumer GPU tier, which means a solo novelist with a modest desktop can produce serialized video content that visually competes with studio-backed productions.
Novel-to-Video Workflow vs Manual Scene-by-Scene Generation
The pipeline is built for authors and publishers who hold a complete manuscript and want a) consistent characters across every episode, b) the ability to compare three engine aesthetics side by side before settling on a visual direction, and c) a repeatable template for future novel adaptations. If you are writing a single scene or a short script under 1,000 words, the standard script-to-video editor is a better fit because it surfaces engine-specific knobs that the novel-pipeline auto-rewriter intentionally hides for throughput. The novel-to-video workflow trades granular per-shot control for volume throughput and cross-episode consistency. Authors publishing web novels, serialized fiction on platforms like Wattpad or Kindle Vella, and independent publishers who want to test visual formats before committing to full production will find this workflow matches their iteration cadence.
Technical Specifications and Output Format
A typical 10-chapter novel with 5,000-7,000 words per chapter renders in approximately 90-110 minutes end-to-end, including manuscript ingestion, scene-graph construction, all three engine renders at 1080×1920 (9:16 vertical) 60fps, and audio sync for dialogue scenes. The pipeline supports up to 20 distinct character references with per-chapter style locks, auto-generated captions per episode, and a built-in chapter-level review studio where you can re-render any scene against any engine without affecting the rest of the series. Output episodes are delivered as individual MP4 files named by chapter, ready for upload to YouTube, TikTok, or your preferred serialized content platform. For the full picture of how novel-to-video integrates into VoooAI's broader production ecosystem, visit the [Script to Video AI](/script-to-video) hub, which covers multi-engine orchestration, template-driven workflows, and platform-specific optimization for serialized content creators.
Frequently Asked Questions
What file formats does the novel-to-video workflow accept?
TXT, DOCX, and strict Markdown with H2 chapter headings are accepted. Plain TXT or Markdown with one blank line between paragraphs gives the cleanest scene-graph parse. EPUB and PDF are not currently supported—export your manuscript as DOCX or TXT before uploading.
How long does it take to render a full novel into a video series?
A 10-chapter novel (5,000-7,000 words per chapter) renders in approximately 90-110 minutes end-to-end across all three parallel engines. This includes manuscript ingestion, scene-graph construction, parallel engine rendering, and audio sync for dialogue scenes.
Can I re-render a single chapter without regenerating the whole series?
Yes. The built-in chapter-level review studio lets you re-render any scene in any chapter against any of the three engines without affecting the rest of the series. Character references, style locks, and episode continuity are preserved.
How does VoooAI maintain character consistency across chapters and engines?
A shared reference-image pool locks facial geometry, clothing, and lighting across all three video engines. Upload one face reference per protagonist at the top of the workflow, and every scene—regardless of which engine renders it—receives the same visual identity.
What are the minimum hardware requirements for the novel-to-video pipeline?
The pipeline runs on a single consumer GPU with 24GB VRAM—the same tier as an RTX 4090. This hardware tier supports all three engines (Kling O3, Wan2.6, Seedance 2.0) running in parallel without swapping models. Cloud rendering is available for users without a compatible local GPU.